OpenAI Umumkan o3 dan o3-mini, Bisa Pecahkan Soal Matematika Level Dewa

- Perusahaan pembuat chatbot ChatGPT, OpenAI resmi mengumumkan dua model kecerdasan buatan (artificial intelligence/AI) terbarunya, o3 dan o3-mini.
o3 dan o3-mini merupakan model AI yang memiliki kemampuan bernalar (reasoning). Dengan kemampuan ini, kedua model AI tersebut diklaim mampu menyelesaikan sebuah persoalan dengan cara berpikir yang lebih logis, mirip seperti manusia.
Seperti namanya, o3 merupakan suksesor dari o1 yang diperkenalkan September lalu. Kemudian o3-mini adalah model AI reasoning versi lebih ringan dan lebih murah dari o3, sekaligus merupakan penerus dari o1-mini.
Dalam sejumlah pengujian internal, OpenAI mengeklaim o3 jauh lebih pintar dari o1 untuk menyelesaikan berbagai persoalan matematika. Salah satunya adalah kompetisi matematika level "dewa" alias internasional, American Invitational Mathematics Exam (AIME) 2024.
Pada pengujian AIME 2024, o3 disebut mampu menyelesaikan hampir semua soal di kompetisi ini dengan nilai 96,7 persen (hanya salah satu soal). Di sisi lain, o1 hanya mampu mendapatkan skor 83,3 persen untuk pengujian serupa.
Baca juga: OpenAI Akhirnya Rilis Sora, AI Pembuat Video dari Teks
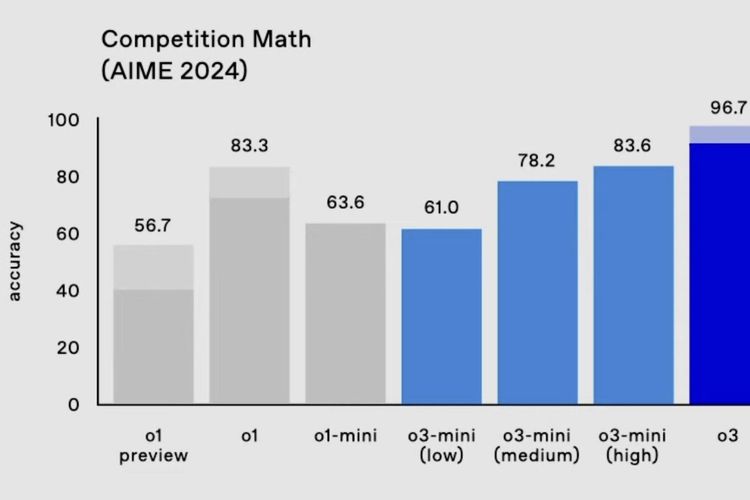 Ilustrasi performa model AI reasoning OpenAI o1 dan o3 dalam menyelesaikan soal AIME 2024.
Ilustrasi performa model AI reasoning OpenAI o1 dan o3 dalam menyelesaikan soal AIME 2024.o3-mini, dalam mode penalaran "High", juga diklaim lebih jago menjawab soal-soal AIME 2024 dibanding o1 dan o1-mini dengan skor 83,6 persen. o1-mini sendiri memiliki skor akhir 63,6 persen.
Selain pengujian soal AIME 2024, OpenAI juga mengeklaim o3 dapat menjawab berbagai soal sains di level universitas yang tergabung dalam kelompok soal GPQA Diamond. Di pengujian ini, o3 mendapatkan skor 87,7 persen.
o3, lanjut OpenAI, juga unggul di beberapa pengujian alias benchmark populer yang berkaitan dengan reasoning.
Beberapa di antaranya seperti SWE-Bench Verified (programming) dengan skor 22,8 poin, Codeforces (coding) dengan skor 2.727 poin, serta Frontier Math milik EpochAI dengan kemampuan penyelesaian soal 25,2 persen.
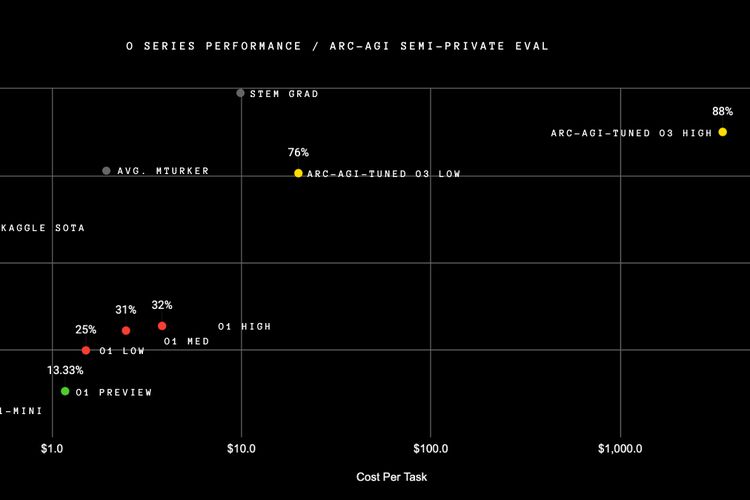 Performa benchmark ARC-AGI untuk model AI reasoning o1 dan o3.
Performa benchmark ARC-AGI untuk model AI reasoning o1 dan o3.Di luar aneka benchmark di atas, o3 juga disebut memiliki performa nyaris sempurna untuk pengujian kebolehan Artificial General Intelligence (AGI), yaitu ARC-AGI.
Pengujian ini biasanya dipakai untuk mengetes apakah AI dapat memiliki kemampuan pola pikir seperti manusia atau tidak.
Dalam skala 0-100 persen, o3 memiliki skor performa ARC-AGI mencapai 76 persen untuk mode "Low" dan 88 persen untuk mode "High". Di sisi lain, o1 dalam hanya memiliki skor berkisar di angka 20-30 persen untuk berbagai mode, dari Low hingga High.
Baca juga: Google Rilis Model AI Veo 2, Bikin Video dari Teks Makin Realistis
Tidak lebih cepat dari GPT-4o dan o1
Secara umum, model AI reasoning akan merespons pertanyaan atau kueri pengguna lebih lama dari model AI "reguler". Hal ini disebabkan karena o3 sejatinya akan berpikir dan menghitung berulang kali sebelum mereka menjawab respons dari pengguna.
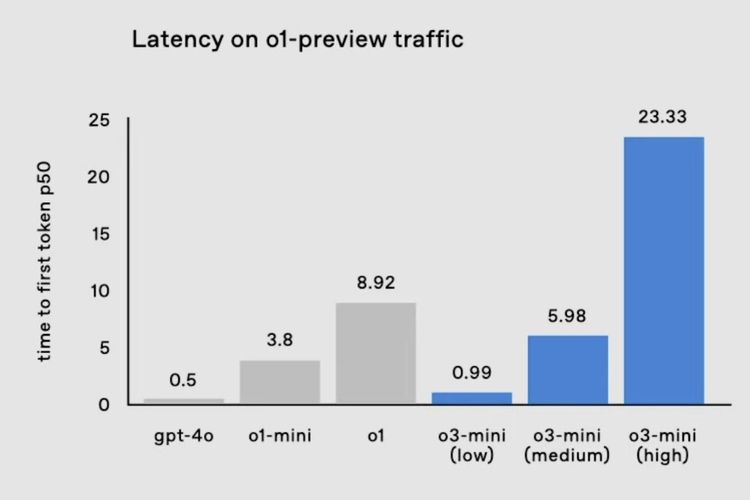 Ilustrasi performa model AI reasoning OpenAI o1 dan o3 dalam menyelesaikan soal AIME 2024.
Ilustrasi performa model AI reasoning OpenAI o1 dan o3 dalam menyelesaikan soal AIME 2024.Ketika dibandingkan, o3 untuk mode High akan merespons pengguna 23 detik setelah kueri diterima. Pada ChatGPT yang memakai GPT-4o, proses ini hanya akan berlangsung sekitar 0,5 detik.
Terkini Lainnya
- AMD Rilis Ryzen 8000 HX, Chip Murah untuk Laptop Gaming
- Trump Bebaskan Tarif untuk Smartphone, Laptop, dan Elektronik dari China
- Apple Kirim 600 Ton iPhone dari India ke AS
- LAN: Pengertian, Fungsi, Cara Kerja, Karakteristik, serta Kelebihan dan Kekurangannya
- 3 Game Gratis PS Plus April 2025, Ada Hogwarts Legacy
- Trafik Broadband Telkomsel Naik 12 Persen saat Idul Fitri 2025
- 3 Cara Menyimpan Foto di Google Drive dengan Mudah dan Praktis
- Samsung Galaxy A26 5G: Harga dan Spesifikasi di Indonesia
- Google PHK Ratusan Karyawan, Tim Android dan Pixel Terdampak
- Harga iPhone 12, 12 Mini, 12 Pro, dan iPhone 12 Pro Max Second Terbaru
- Apa Itu e-SIM, Bedanya dengan Kartu SIM Biasa?
- WordPress Rilis Fitur Baru, Pengguna Bisa Bikin Website Pakai AI
- INFOGRAFIK: Mengenal Teknologi E-SIM yang Kini Digunakan iPhone
- WA Down di Berbagai Negara, Tidak Hanya Indonesia
- WhatsApp Down, Pengguna Tidak Bisa Kirim Chat ke Grup
- Pemakaian Cerdas dan Etis ChatGPT di Telepon dan WhatsApp (Bagian I)
- Temuan Amnesty International: Polisi Serbia Mata-matai Ponsel Jurnalis Pakai Spyware
- LG Rilis TV Transparan Nirkabel Pertama di Dunia, Harganya Nyaris Rp 1 Miliar
- Mengulik Lenovo Yoga Pro 7, Laptop Premium dengan Kecerdasan AI untuk Para Kreator
- Bocoran Tampang Samsung Galaxy S25 Plus dan S25 Ultra, Punya Sudut Berbeda